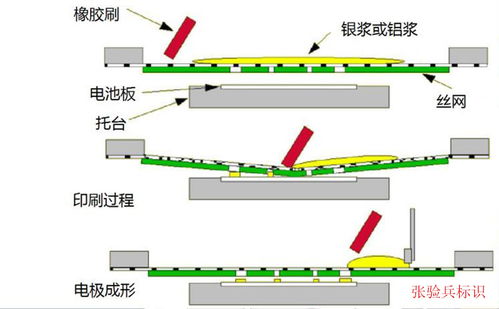
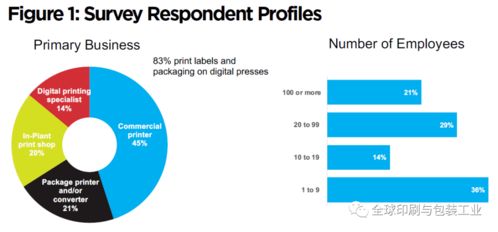
数字化印模:从数据到文章的全过程

==================
1. 收集数据-------
在开始任何数据驱动的项目之前,收集数据是第一步。你需要确定你的目标,然后寻找最能满足这些目标的数据源。数据可以来自各种来源,包括公开数据库、社交媒体、调查问卷等。在收集数据时,应确保数据的准确性、可靠性和完整性。
2. 数据清洗-------
在收集到数据后,需要进行数据清洗,以消除错误、重复和异常值。这可以通过各种方法实现,包括数据筛选、数据转换和数据重塑。这个过程可以帮助提升数据的质量,并减少模型训练时可能出现的错误。
3. 数据预处理--------
数据预处理是机器学习的重要步骤,它包括缩放、标准化、编码转换等。这些步骤可以使得数据更容易被模型理解和使用。例如,如果模型需要在一定的数值范围内才能正常工作,那么你可能需要将数据进行缩放。或者,如果数据中包含分类信息,你可能需要将其转换为模型可以理解的格式。
4. 特征提取-------
特征提取是从数据中提取有意义的信息的过程。这可能涉及到对数据的深入理解,以及将其转化为模型可以使用的形式。特征可以是简单的统计量,如平均值、中位数等,也可以是更复杂的统计模型,如主成分分析(PCA)或词袋模型。
5. 模型构建-------
在特征提取之后,我们可以开始构建模型。这可能涉及到选择合适的算法,如线性回归、决策树、神经网络等。在构建模型时,我们需要考虑模型的复杂性和可解释性。我们希望模型能够尽可能地解释数据中的模式,同时避免过拟合和欠拟合的情况。
6. 模型优化-------
一旦模型构建完成,我们还需要进行模型优化。这可能涉及到调整模型的参数,或者使用交叉验证等方法来优化模型的性能。我们的目标是最小化模型的误差,同时最大化模型的泛化能力。
7. 模型评估-------
在模型优化完成后,我们需要对模型进行评估。这可以通过使用测试集来完成,测试集是独立于训练集和验证集的数据集。我们希望评估出的性能指标能够真实地反映出模型在未来的表现。常见的评估指标包括准确率、精确率、召回率和F1分数等。
8. 文章生成-------
最后一步是将模型的结果转化为文章。文章应该清晰、简洁地描述你的发现和结论。在撰写文章时,应确保数据的准确性和完整性,同时避免使用过于复杂的术语或行话。文章的结论部分应该总结你的发现,并指出你的研究在未来可能的应用和价值。